基于fastText和BERT的恶意软件检测与分类 Malware Detection and Classification Using fastText and BERT
摘要
在各种网络攻击类型中,恶意软件是对计算机系统的最大威胁,它给机构和个人造成了巨大的经济损失。恶意软件的种类日益增多,新类型层出不穷,它们很容易通过我们经常使用的电子邮件、网站、网络应用程序等注入载体感染我们的计算机。自动检测它们并保护我们的计算机系统免受恶意软件威胁是非常重要的。分析方法可用来保护我们的计算机系统免受恶意软件的威胁。动态分析对于获取软件在计算机系统上的行为信息非常有效,可以获取恶意软件的API调用序列信息。然而,API调用序列可能太长,难以理解。本文提出将API调用顺序纳入净化和优化过程。此行为信息用于自动分类任务,然后用于使用fastText和BERT算法的分类和单词表示任务。在三个不同的开放数据集上使用它来观察该方法的成功。fastText模型在分类和检测任务上优于BERT模型。
关键词 - 恶意软件、动态分析、自然语言处理、Fasttext、Bert
1 介绍
恶意软件是所有恶意软件的总称。它被定义为为非法使用、利用、破坏和类似的计算机系统恶意目的而编写的所有软件,并且在最终用户不知道有害影响的情况下被纳入系统。它在用户不知情或误导用户的情况下感染计算机系统,并执行其恶意目的b[1]。恶意软件的威胁不应掉以轻心。根据埃森哲安全发布的报告,在他们分析的1000次网络攻击中,恶意软件是最常见的网络攻击类型,对组织造成的经济损失最高,平均为260万美元。根据独立的it安全机构(AV-TEST institute)的结果,已知的恶意软件超过6.2亿,每天检测到的新恶意软件超过35万个。由于每天都有大量的恶意软件出现,基于签名的反病毒系统不能提供完全的保护。为了克服这个问题,应该对软件进行分析,以确保它不会对计算机安全构成威胁。据研究人员称,静态分析方法在不运行恶意软件的情况下分析二进制文件非常有用,但由于代码混淆技术[4],这种方法变得非常困难。无论这里的混淆技术有多复杂,恶意软件都必须展示其恶意行为以实现其恶意目的。软件的行为分析不处理代码的结构,它的签名,以及软件改变了多少。这种技术被称为动态分析,它通常是对软件在安全虚拟系统[5]上执行时的运行时进行分析。分析不只是通过观察不同。软件在注册表中所做的更改,文件的更改,软件将自己添加到自动启动位置,监控软件创建的信息流,监控系统和函数调用的信息,分析软件操作系统提供的API调用,等等。它是所有动作b[6]的总和。在动力分析中,参数太多。尽管有一些有用的工具可以检查相关领域,但仍有许多我们需要检查且可能被忽视的领域。与查看所有这些相关领域不同,可以分析表示软件和操作系统之间交互的API调用模式。API系统调用、系统服务、文件管理、同步、网络、注册表修改、捕获功能等。它支持操作系统提供的各种关键操作,是软件在系统上的所有动作。例如,在非自动化分析中,我们使用regshot工具[7]观察注册表中的更改。同时,我们使用Wireshark[8]进行网络分析,使用进程监视器[9]进行进程/线程活动,并使用许多类似的分析工具进行观察。而不是查看所有这些,捕获API系统调用等同于此。
恶意软件是所有恶意软件的总称。它被定义为为非法使用、利用、破坏和类似的计算机系统恶意目的而编写的所有软件,并且在最终用户不知道有害影响的情况下被纳入系统。它在用户不知情或误导用户的情况下感染计算机系统,并执行其恶意目的b[1]。恶意软件的威胁不应掉以轻心。根据埃森哲安全发布的报告,在他们分析的1000次网络攻击中,恶意软件是最常见的网络攻击类型,对组织造成的经济损失最高,平均为260万美元。根据独立的it安全机构(AV-TEST institute)的结果,已知的恶意软件超过6.2亿,每天检测到的新恶意软件超过35万个。由于每天都有大量的恶意软件出现,基于签名的反病毒系统不能提供完全的保护。为了克服这个问题,应该对软件进行分析,以确保它不会对计算机安全构成威胁。据研究人员称,静态分析方法在不运行恶意软件的情况下分析二进制文件非常有用,但由于代码混淆技术[4],这种方法变得非常困难。无论这里的混淆技术有多复杂,恶意软件都必须展示其恶意行为以实现其恶意目的。软件的行为分析不处理代码的结构,它的签名,以及软件改变了多少。这种技术被称为动态分析,它通常是对软件在安全虚拟系统[5]上执行时的运行时进行分析。分析不只是通过观察不同。软件在注册表中所做的更改,文件的更改,软件将自己添加到自动启动位置,监控软件创建的信息流,监控系统和函数调用的信息,分析软件操作系统提供的API调用,等等。它是所有动作b[6]的总和。在动力分析中,参数太多。尽管有一些有用的工具可以检查相关领域,但仍有许多我们需要检查且可能被忽视的领域。与查看所有这些相关领域不同,可以分析表示软件和操作系统之间交互的API调用模式。API系统调用、系统服务、文件管理、同步、网络、注册表修改、捕获功能等。它支持操作系统提供的各种关键操作,是软件在系统上的所有动作。例如,在非自动化分析中,我们使用regshot工具[7]观察注册表中的更改。同时,我们使用Wireshark[8]进行网络分析,使用进程监视器[9]进行进程/线程活动,并使用许多类似的分析工具进行观察。而不是查看所有这些,捕获API系统调用等同于此。
2 相关工作
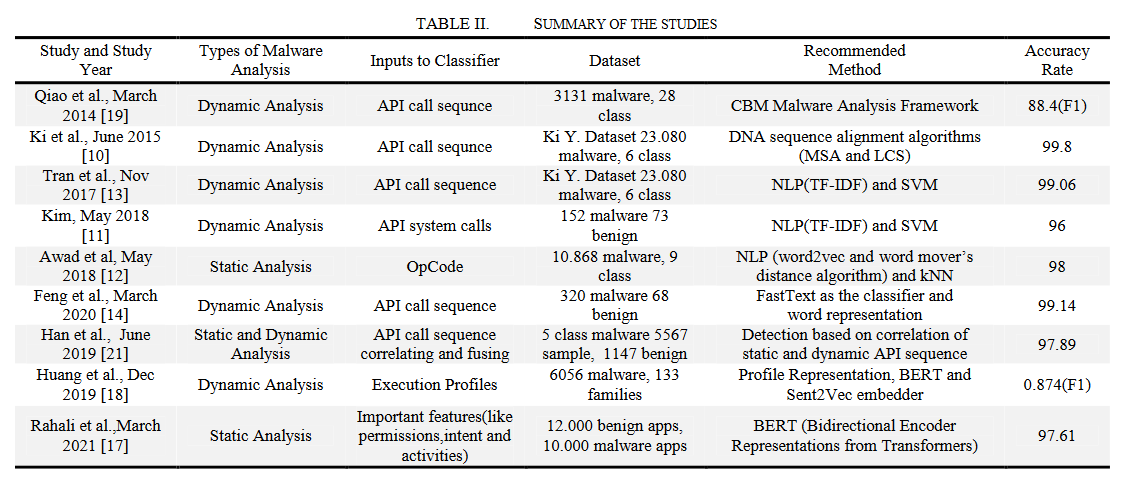
表2显示了恶意软件检测和分类研究中使用的方法、该方法使用的属性、有关数据集的信息、推荐的方法和准确率。在涉及自然语言处理技术的研究中,研究人员使用静态分析或动态分析方法提取特征并开发模型。Kim[11]使用自然语言处理方法分析了Windows API系统的软件调用属性,采用了动态分析方法,比静态分析更具有泛化性。API系统调用特征n图分组、TF-IDF方法、SVM机器学习算法成功检测恶意软件,准确率达96%。Awad等人建议将从恶意软件分析中提取的特征建模为一种语言。采用静态分析方法对9类恶意软件组成的数据集进行分析,并利用word2vec模型提取同一类恶意软件之间的语义上下文。他们利用k近邻算法(kNN)和交叉验证方法对未知恶意软件样本进行分类,分类准确率高达98%。使用自然语言处理方法n-gram、doc2vec、TF-IDF技术将API调用序列转换为数值向量,对恶意软件进行分类。目前提出了三种不同的NLP方法:TF-IDF、PV-DM(类似于skip-gram)和PV-DBOW(类似于cbow)。该实验采用TF-IDF技术和支持向量机对两个家族进行分类,准确率达到99.06%,是所有实验中准确率最高的。Feng等人[14]建议动态提取不同恶意软件类别的API调用序列模式进行恶意软件检测,然后使用fastText作为分类器和单词表示。他们将fastText算法应用于两个开放的恶意软件数据集,CSDMC[15]数据集的准确率为99.14%,Kim等人编写的APIMDS[16]数据集的准确率为97.60%。Rahali和Akhloufi[17]基于Transformers架构进行恶意软件检测。已获得功能的静态源代码分析的Android应用程序。基于bert的模型对二分类的准确率为97.61%,对多分类的准确率为91.02%。Huang等人[18]通过VMI生成了恶意软件的动态行为概况。他们能够用一种名为RasMMa的主题挖掘算法,将62种选定的Windows API特性与常见行为进行分组。通过以这种方式创建配置文件表示,它用于捕获BERT和Sent2vec嵌入模块与恶意软件的API调用之间的关系。通过这种方法,以前收集的恶意软件家族可以根据其相似性成功地分类新发布的恶意软件的行为痕迹。根据实验结果,他们获得了87.4%的F1分数。通过降低恶意软件的噪声信息,研究人员可以使用特殊的方法对恶意软件进行分类。Qiao等人[19]提出了一个名为CBM的框架,该框架通过将从Cuckoo沙盒接收到的API调用序列与BBIS和CARL算法进行转换,可以被Malheur识别。它可以通过降低API调用中的高可重复性来进一步压缩报告,同时保持或提高其算法的性能。在他们的实验中,他们减少了报告大小,节省了时间,并且在28个恶意软件类别的分类中实现了88.4%的F1度量。Ki等人[10]提出利用DNA序列比对算法对恶意软件动态分析得到的API调用序列进行分类。多亏了他们的算法,他们能够将恶意软件的恶意功能与API调用进行比较,并且他们减少了使用恶意软件的混淆技术避免检测的可能性。通过这种方式,他们能够达到99.8%的准确率。Cho等[20]生物信息学可以使用常用的序列比对方法检测恶意软件。通过从调用序列中删除恶意软件的冗余和嘈杂的API调用,他们能够将处理时间减少91%到99%。Han等人[21]将静态分析和动态分析得到的API调用序列结合起来,创建了一个混合API调用序列。它们通过在连接之前从API调用中去除噪声和冗余API调用来进行净化。关联和融合过程基于API调用序列的语义信息。研究表明,机器学习技术随机森林算法检测恶意软件的准确率为97.89%。
3 方法
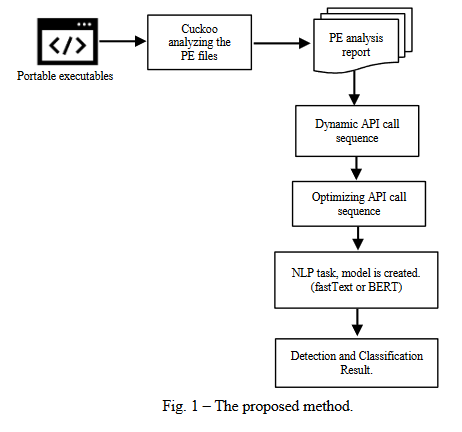
该研究的思想是,软件API调用序列可以被视为一种语言,软件通过这种语言与系统对话并做它想做的事情,这种语言可以通过自然语言处理方法学习。提出的方法是优化软件的API调用序列,以提高NLP任务检测和分类的准确性和速度。图1总结了提出的方法。首先,选取恶意软件和良性样本完成检测和分类任务。下一步是在软件隔离分析环境中使用动态分析方法提取API调用字符串属性。利用该方法对提取的特征进行了优化。最后,它与单词表示算法结合使用。将该方法与fastText和BERT两种不同的基于词嵌入技术结合使用。此外,还比较了这些词嵌入技术的准确率结果。
A.分析环境
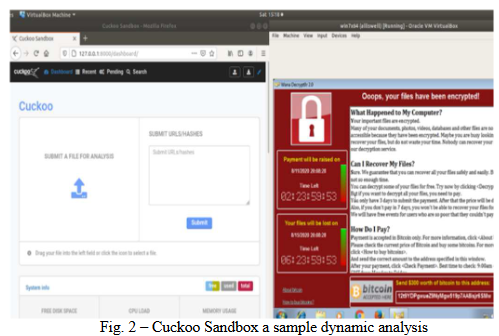
在检查恶意软件的影响时,确保它不会对系统造成永久性损害的最佳方法是以受控的方式在与主机系统隔离的虚拟区域中运行它。提供这种隔离环境的工具称为沙盒[22]。本研究选择开放源代码的布谷鸟沙盒环境作为分析环境。在系统上的布谷鸟沙盒中,可以观察软件样本的行为,并记录API调用。该软件产生的网络流量即使经过加密也可以被记录下来。受软件影响的系统的内存分析可以通过安装在cuckoo[23]上的附加工具来执行。该分析工具详细报告软件在执行过程中的行为,并使软件能够以自动化的方式进行分析。为了防止分析机在分析阶段干扰软件,已经关闭了会对分析产生不利影响的防火墙和网络服务,只关注软件产生的行为结果。图2显示了研究中使用的分析环境分析恶意软件的时刻。每次分析结束后,分析机回到清洁状态,所有样品自动连续分析。通过对杜鹃沙盒环境下数据集中的软件进行分析,得到Json报表。除了报表API调用,它还提供了许多特性。然而,在研究中,恶意软件检测仅使用API调用序列特征。
B.优化API调用顺序
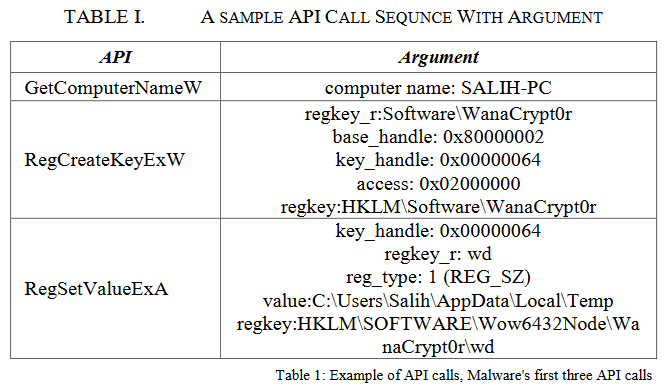
杜鹃沙盒分析环境中获得的数据包括静态分析和行为分析结果。API调用序列是杜鹃沙盒行为分析的结果,详细描述了其参数,如表1所示。选取的特征是不包含参数的API调用序列。这里遇到的问题是,软件在它们运行的任何循环中或由于相同的点击而产生太多冗余和嘈杂的API调用。通常,它会创建嘈杂和冗余的API调用,以混淆恶意软件中的恶意行为。通过去除这些噪声和冗余调用,可以节省用于模型训练和分类的时间。但是这里需要注意的是,API调用虽然被视为冗余和噪声,但也可能是有价值的分类信息。因此,从API调用序列中删除的API调用根据噪声和API调用的冗余数量进行标记。通过这种方式,进行单词表示的算法在这里不会失去解释,并且可以执行更快的模型训练和分类过程。
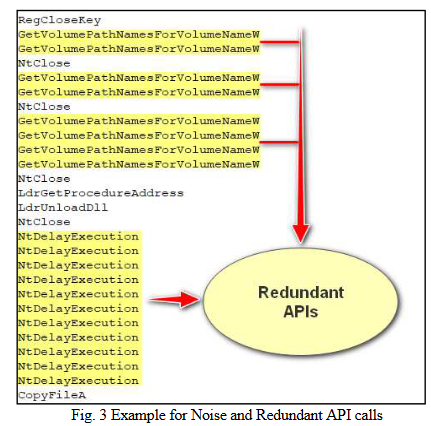


图3。“Virus.Win32.VB。分析显示了恶意软件执行的API调用序列。优化算法非常简单,去掉了重复的API调用[20,21]。它在它的位置添加标签;如果API调用的重复次数小于10,则添加“low冗余”标签,如果在10到100之间,则添加“medre冗余”,如果在100到1000之间,则添加“high冗余”,最后,如果它大于1000,则添加“veryhigh冗余”标签。图4显示了从冗余API调用中提炼的API调用序列。噪声API调用是重复的API调用模式。API标签按上述相同的数字比例添加。API标签如下:“LowNoisy”,“MedNoisy”,“HighNoisy”和“VeryHighNoisy”。标记过程中的数字根据对数尺度确定。因为如果在不添加标记的情况下删除重复的API调用,那么减少重复的速度将达到对数级[19]。图5显示了经过清理的噪声和冗余API调用的API调用序列,这是一个优化版本。
c.fastText
fastText是一个开源的自然语言处理库,由Facebook研究人员[24]创建和支持。该库可以将单词表示表示为向量并进行句子分类。fastText显示为word2vec模型的扩展。Word2vec将文本中的每个单词视为一个实体,并为每个单词创建一个向量。在fastText中,单词的向量是其字符的n-gram和。它计算每个单词的n-gram字符表示。通过这种方式,由于fastText可以在子词级别进行训练,因此它可以理解单词中的附件,并计算在训练阶段未遇到的单词的表示。
d.BERT
BERT是一个开源的自然语言处理软件框架,由谷歌人工智能研究人员[25]创建和支持。它是“来自transformer的双向编码器表示”的缩写。BERT基于Transformer架构,该架构学习文本中单词和子单词之间的上下文关系,并将文本作为一个整体而不是以特定顺序处理。通过这种方式,可以计算出单词的左右上下文,这就是为什么它被称为BERT双向模型[26]。非上下文模型只创建一个单词表示,而不考虑该单词在文本中的使用。例如,在句子“match the words”和“light the match”中,单词“match”将具有相同的表示。BERT是一个上下文模型,它为句子中与其他单词相关的单词产生不同的表示。BERT使用WordPiece模型进行标记化任务。标记化是指将文本分成单词或子单词。WordPiece模型是一种将单词划分为子词的算法。多亏了WordPiece, BERT可以识别语法后缀,并计算在训练阶段没有遇到的单词的表示形式。